|
I am currently working at The International Digital Economy Academy (IDEA) as Computer Vision Engineer, advised by Prof. Lei Zhang . In 2021, I got my bachelor's degree from MAC Lab in Xiamen University advised by Associate Prof. Yiyi Zhou and Prof. Rongrong Ji. I'm primarily interested in researching vision foundation models, object detection and segmentation, and multi-modal learning. I'm also passionate about open-source projects in AI community. The research work and open-source projects I'm involved in have garnered almost 20.0K stars on Github. Email / Google Scholar / Resume / Github / ZhiHu |
|
See full list at Google Scholar. (* indicates equal contribution, # indicates corresponding author). Representative papers or projects are highlighted. |
|
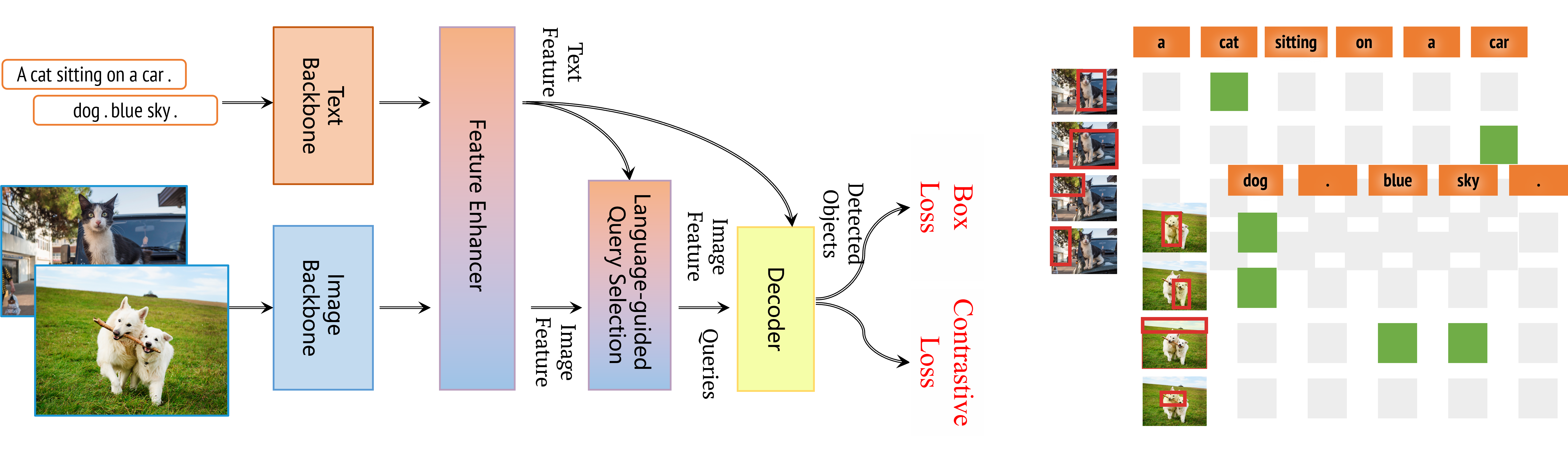
Tianhe Ren*, Qing Jiang*, Shilong Liu*, Zhaoyang Zeng*, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, Yuda Xiong, Hao Zhang, Feng Li, Peijun Tang, Kent Yu, Lei Zhang# Tech report, May. 2024 Best teamwork! IDEA Research's most capable open-world detection model series. |

|
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, Lei Zhang# Tech report, Jan. 2024 An overview technical report about our Grounded-SAM project, involving its base pipeline and more applications. |
|
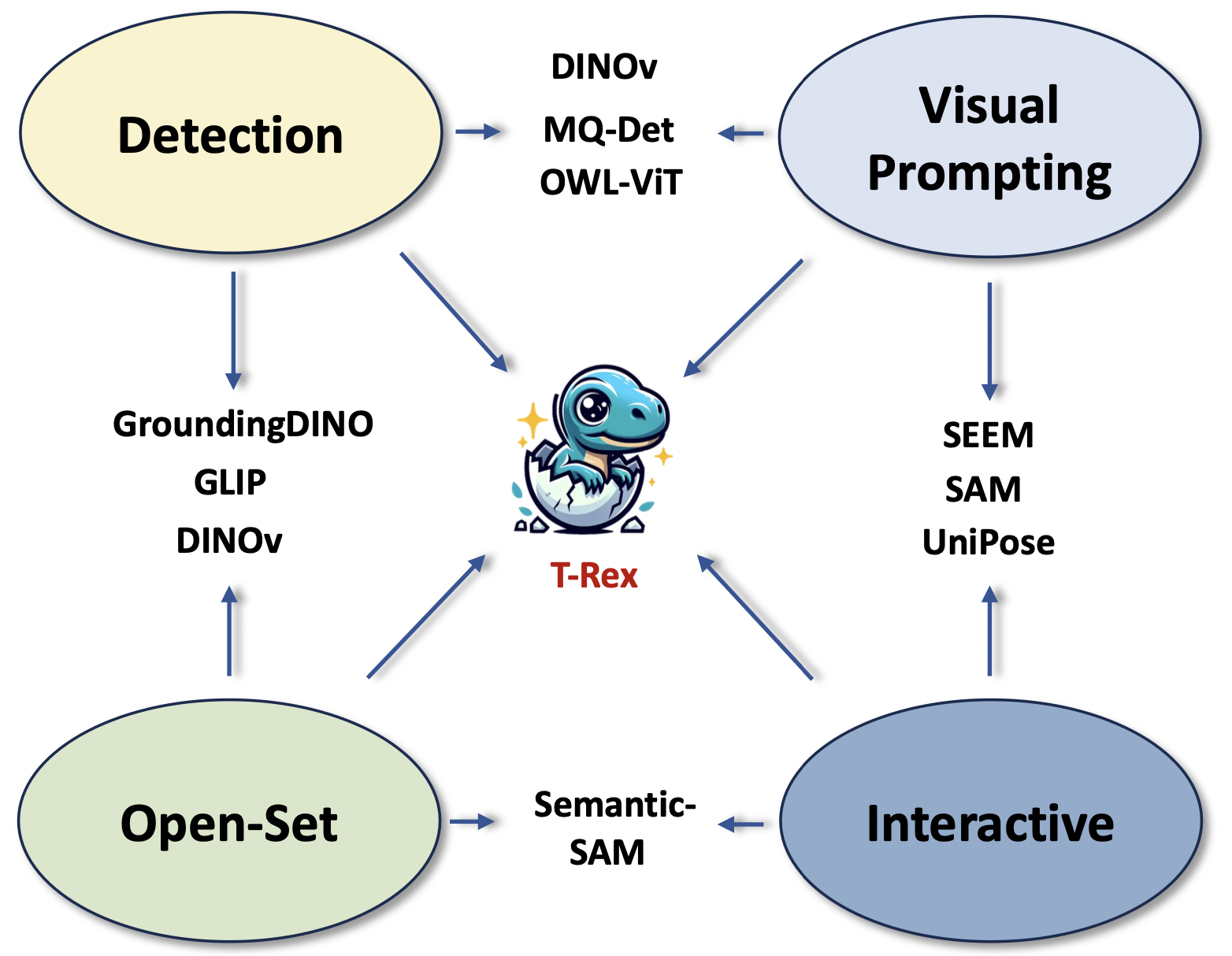
Qing Jiang, Feng Li, Tianhe Ren, Shilong Liu, Zhaoyang Zeng, Kent Yu Lei Zhang# Tech report, Nov. 2023 T-Rex is an object counting model that can first detect then count any objects through visual prompting. |
|
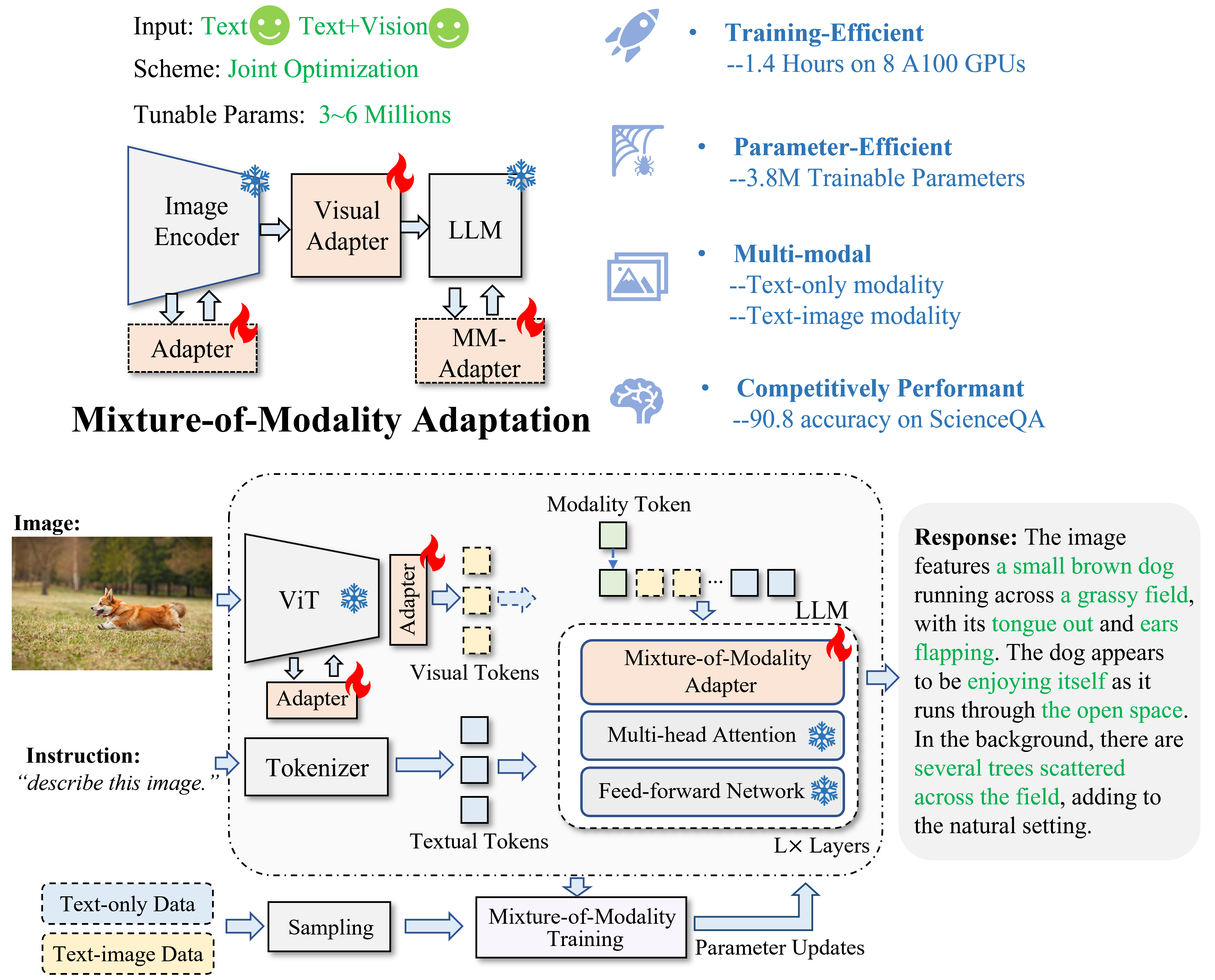
Gen Luo, Yiyi Zhou, Tianhe Ren, Shengxin Chen, Xiaoshuai Sun, Rongrong Ji# Conference on Neural Information Processing Systems (NeurIPS), 2023 A novel parameter-effective method for enhancing large language models' vision-language capabilities. When applied to LLaMA, our LaVIN demonstrates competitive performance in both single-modality and multi-modality tasks, with significant efficiency and reduced training costs. |

|
Tianhe Ren*, Shilong Liu*, Kunchang Li, Ailing Zeng, He Cao, Jiayu Chen , Jing Lin, Feng Li, Hao Zhang, Hongyang Li, Zhaoyang Zeng, Lei Zhang# International Conference on Computer Vision (ICCV) Demo Track, 2023 (Github Trending Top-1 Project) A strong vision foundation model pipeline by combining Grounding-DINO and Segment-Anything-Model which can detect and segment everything with arbitrary text prompts. |
|
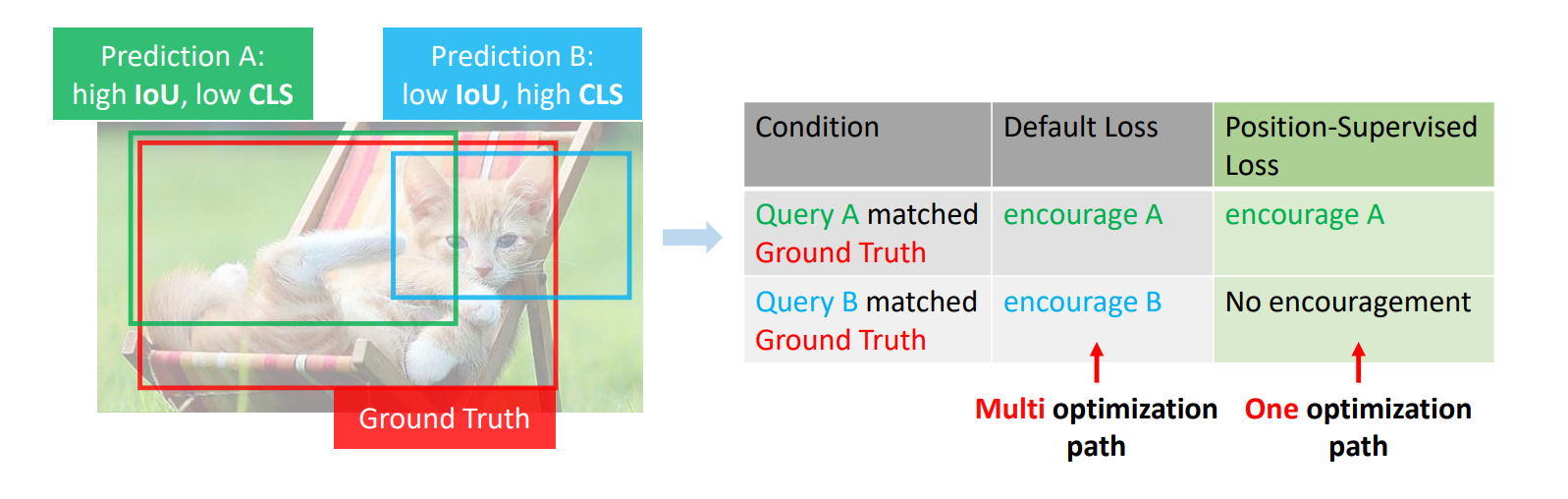
Shilong Liu*, Tianhe Ren*, Jiayu Chen*, Zhaoyang Zeng, Hao Zhang, Feng Li, Hongyang Li, Jun Huang, Hang Su, Jun Zhu, Lei Zhang# International Conference on Computer Vision (ICCV), 2023 Addressed the unstable matching issue in DETR-based models caused by multi-path optimization, by introducing a simple and efficient loss design that uses position metrics to supervise the classification scores of positive examples. |
|
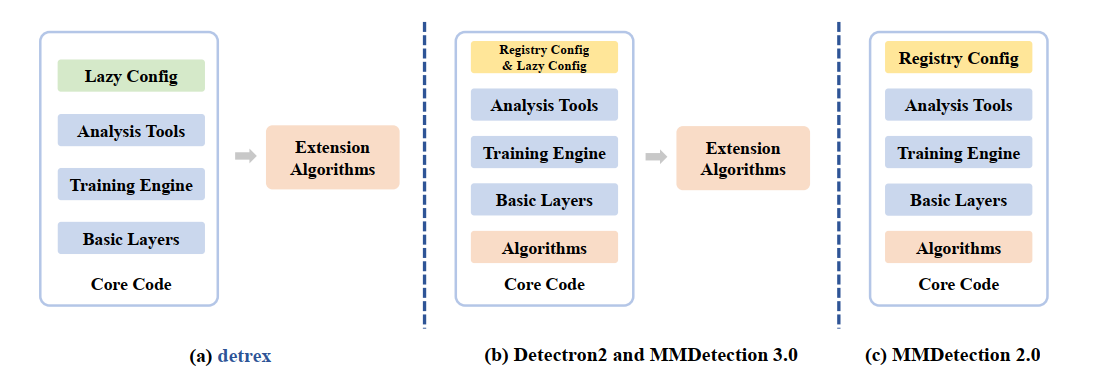
Tianhe Ren*, Shilong Liu*, Feng Li*, Hao Zhang*, Ailing Zeng, Jie Yang, Xingyu Liao, Ding Jia, Hongyang Li, He Cao, Jianan Wang, Zhaoyang Zeng, Xianbiao Qi, Yuhui Yuan, Jianwei Yang, Lei Zhang# Tech report, May. 2023 A standardized and unified benchmarking tool for Transformer-based object detection, segmentation, pose estimation and other visual recognition tasks. |
|
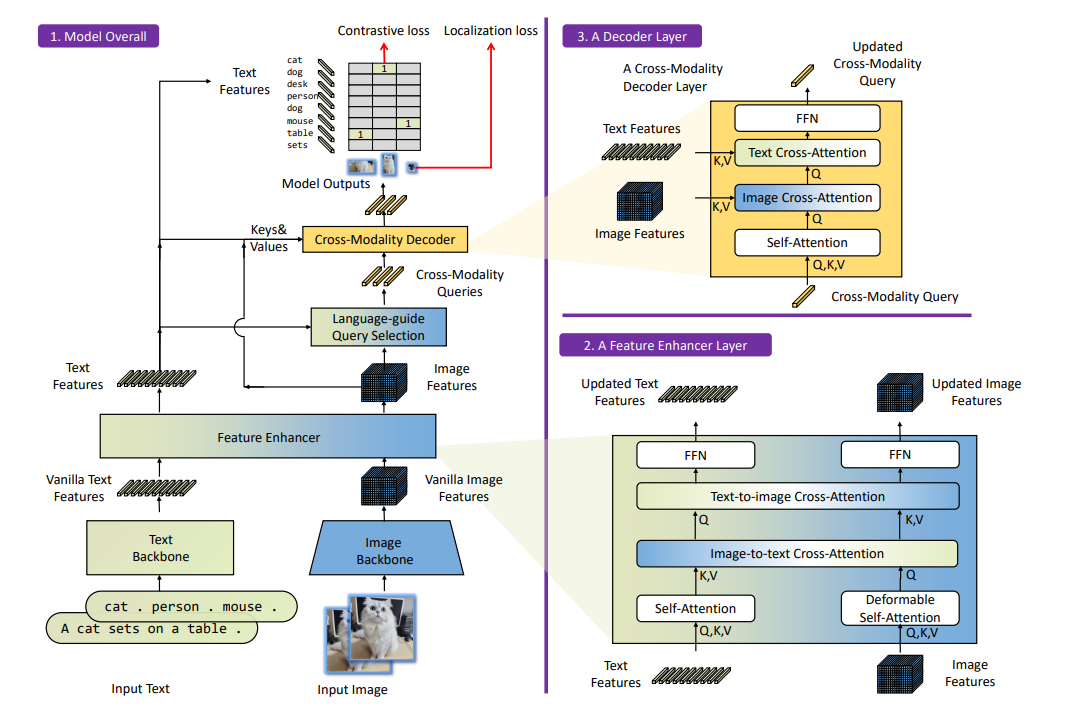
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang# Tech report, Apr. 2023 A simple and strong DETR-based framework for open-set detection, achieving zero-shot 52.5 AP on COCO (training without COCO data). |
|
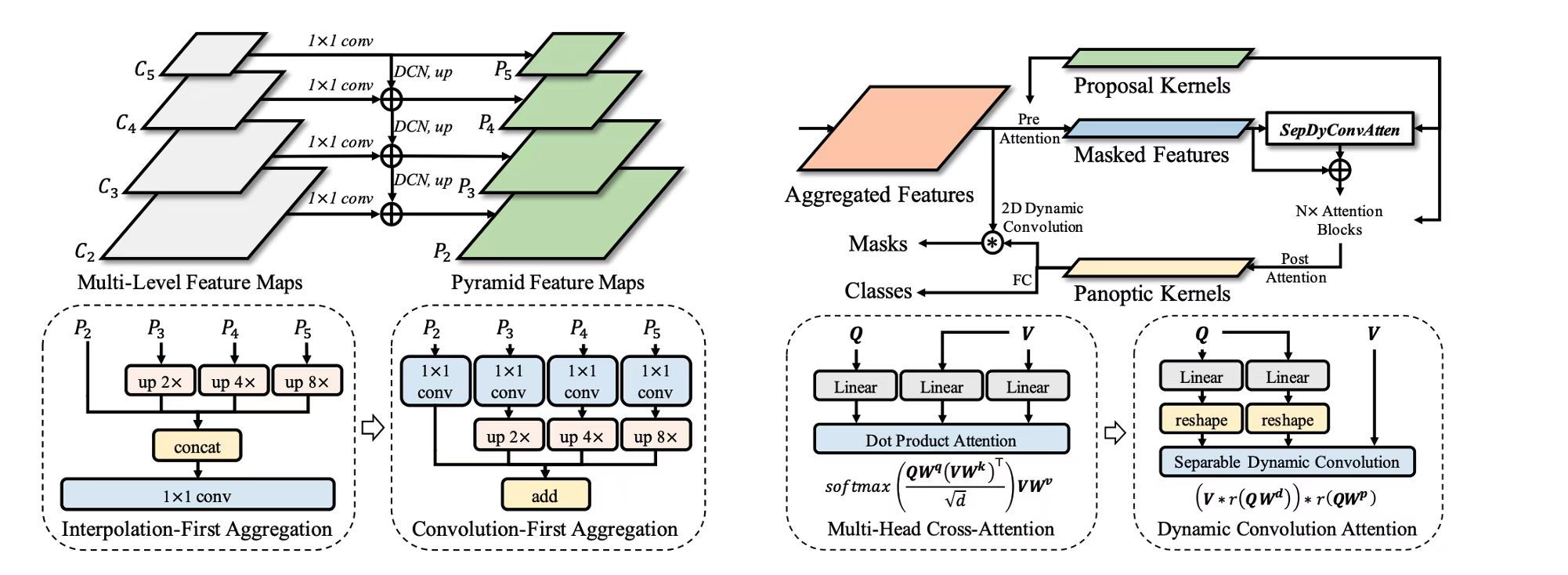
Jie Hu, Linyan Huang, Tianhe Ren, Shengchuan Zhang, Rongrong Ji, Liujuan Cao#, Computer Vision and Pattern Recognition (CVPR), 2023 A novel framework for real-time panoptic segmentation task with competitive performance compared to state-of-the-art methods. |
|
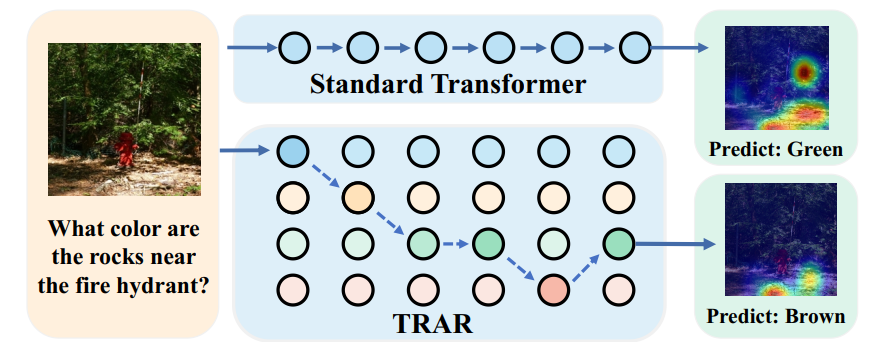
Yiyi Zhou, Tianhe Ren, Chaoyang Zhu , Xiaoshuai Sun#, Jianzhuang Liu, Xinghao Ding, Mingliang Xu, Rongrong Ji# International Conference on Computer Vision (ICCV), 2021 A novel dynamic routing attention mechanism brings a consistent performance gain for a range of vision and language tasks. |
|
Conference Reviewer: |
|
Amazing template by Jon Barron. Big thanks! |