|
Tianhe Ren
I am currently a Ph.D. candidate at The University of Hong Kong, under the supervision of Prof. Xiaojuan Qi.
Previously I was a senior computer vision engineer at The International Digital Economy Academy (IDEA), advised by Prof. Lei Zhang.
In 2021, I got my bachelor's degree from MAC Lab in Xiamen University advised by Associate Prof. Yiyi Zhou and Prof. Rongrong Ji.
I'm primarily interested in researching vision foundation models, object detection and segmentation, and multi-modal learning. I'm also passionate about open-source projects in AI community. The research work and open-source projects I'm involved in have garnered more than 30.0K stars on Github.
✨ My personal avatar is my beloved daughter named Toffee, she is a Minuet (also known as the Napoleon) cat ✨
|

Toffee
|
|
News
2025
-
One paper is accepted to AAAI 2026.
-
One paper is accepted to NeurIPS 2025.
-
One paper is accepted to ICCV 2025.
-
We have released the DINO-XSeeK model, aimed at more accurately detecting objects based more complex text descriptions.
-
One paper is accepted to TPAMI 2025.
|
|
Selected Research
See full list at Google Scholar. (* indicates equal contribution, † indicates corresponding author).
|
|
|
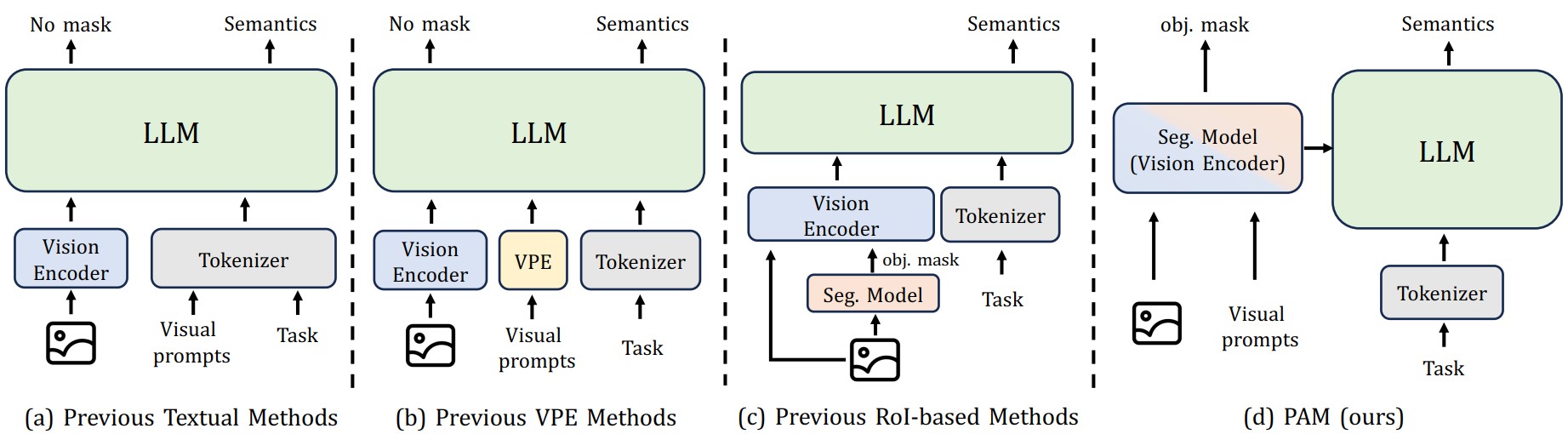
Perceive Anything Model: Recognize, Explain, Caption, and Segment Anything in Images and Videos
Weifeng Lin*,
Xinyu Wei*,
Ruichuan An*,
Tianhe Ren*,
Tingwei Chen,
Renrui Zhang,
Ziyu Guo,
Wentao Zhang,
Lei Zhang,
Hongsheng Li†
Conference on Neural Information Processing Systems (NeurIPS), 2025
|
|
|
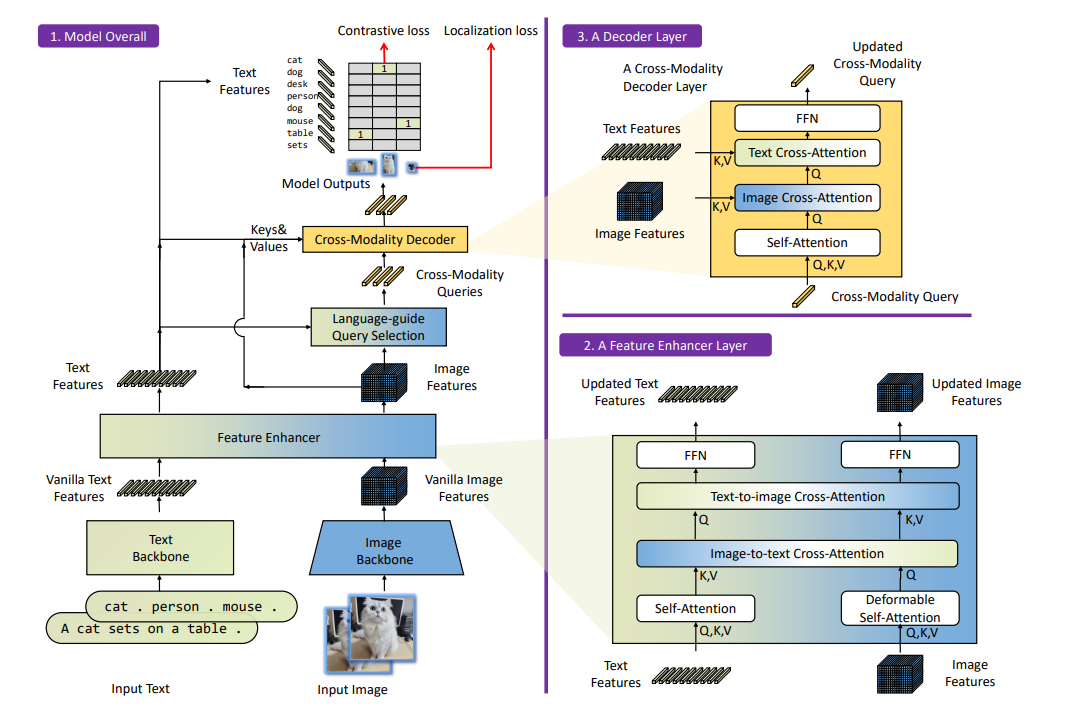
DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
IDEA Research Team
Tech report, Nov, 2024.
|
|
|
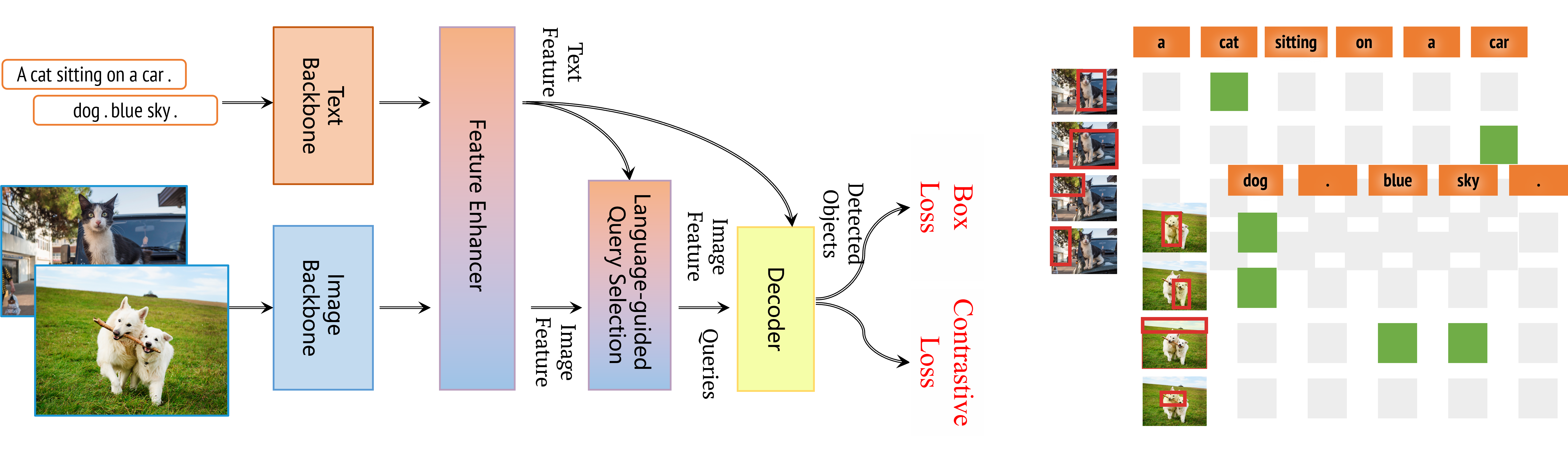
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu,
Zhaoyang Zeng,
Tianhe Ren,
Feng Li,
Hao Zhang,
Jie Yang,
Chunyuan Li,
Jianwei Yang,
Hang Su,
Jun Zhu,
Lei Zhang†
European Conference on Computer Vision (ECCV), 2024.
The 1st Most Influential Paper by PaperDigest.
|
|
|
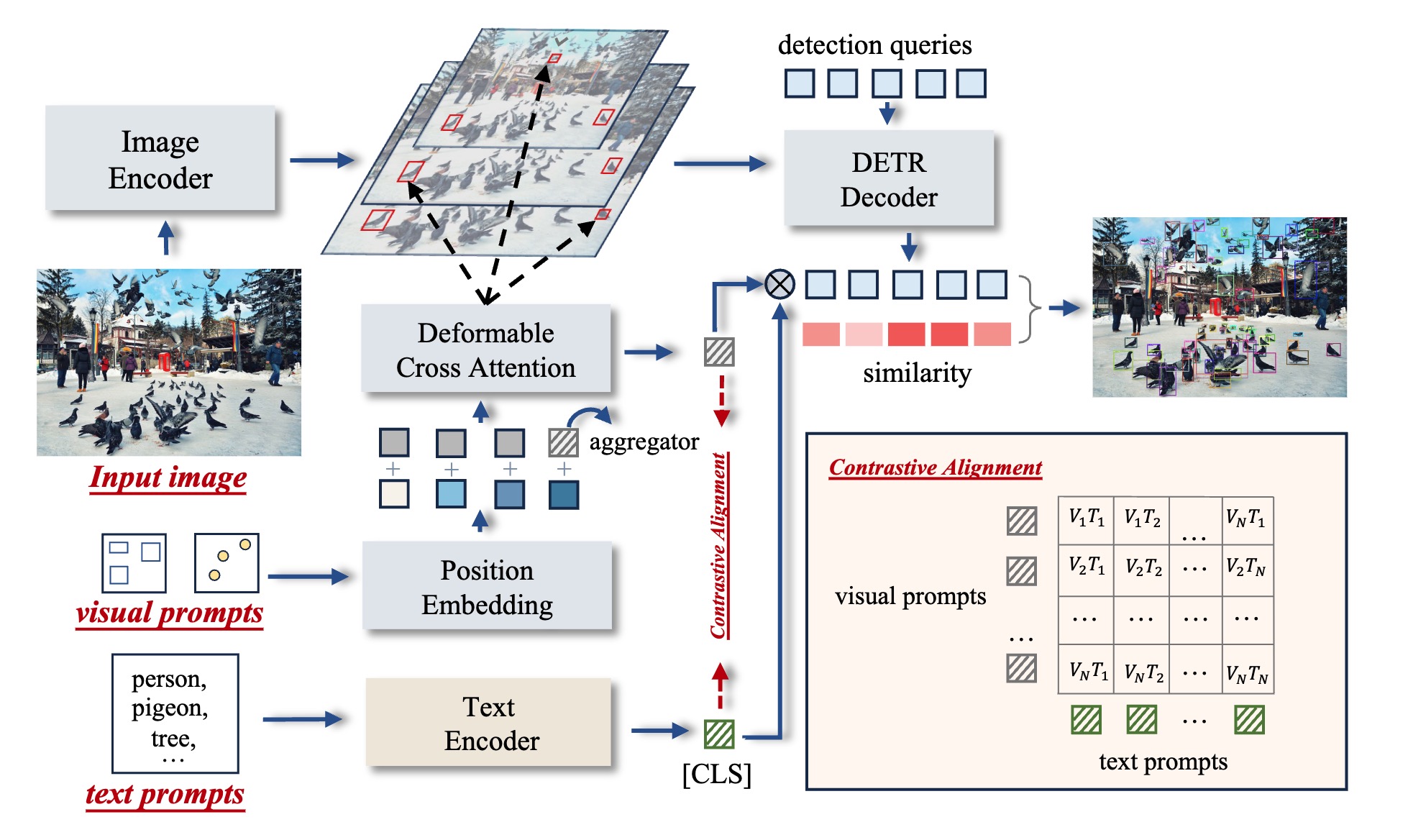
T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy
Qing Jiang,
Feng Li,
Zhaoyang Zeng,
Tianhe Ren,
Shilong Liu,
Lei Zhang†
European Conference on Computer Vision (ECCV), 2024
|
|
|
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
Tianhe Ren*,
Qing Jiang*,
Shilong Liu*,
Zhaoyang Zeng*,
Wenlong Liu,
Han Gao,
Hongjie Huang,
Zhengyu Ma,
Xiaoke Jiang,
Yihao Chen,
Yuda Xiong,
Hao Zhang,
Feng Li,
Peijun Tang,
Kent Yu,
Lei Zhang†
Tech report, May. 2024
|
|
|
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren*,
Shilong Liu*,
Ailing Zeng,
Jing Lin,
Kunchang Li,
He Cao,
Jiayu Chen,
Xinyu Huang,
Yukang Chen,
Feng Yan,
Zhaoyang Zeng,
Hao Zhang,
Feng Li,
Jie Yang,
Hongyang Li,
Qing Jiang,
Lei Zhang†
International Conference on Computer Vision (ICCV) Demo Track, 2023
The 7th Most Influential Paper in the 2024 Computer Vision and Pattern Recognition ArXiv papers by PaperDigest.
|
|
|
Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
Gen Luo,
Yiyi Zhou,
Tianhe Ren,
Shengxin Chen,
Xiaoshuai Sun,
Rongrong Ji†
Conference on Neural Information Processing Systems (NeurIPS), 2023
|
|
|
Detection Transformer with Stable Matching
Shilong Liu*,
Tianhe Ren*,
Jiayu Chen*,
Zhaoyang Zeng,
Hao Zhang,
Feng Li,
Hongyang Li,
Jun Huang,
Hang Su,
Jun Zhu,
Lei Zhang†
International Conference on Computer Vision (ICCV), 2023
|
|
|
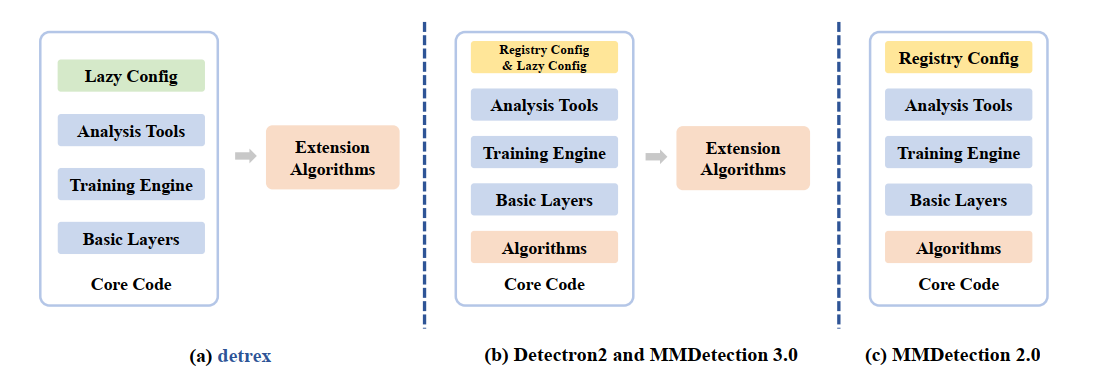
detrex: Benchmarking Detection Transformers
Tianhe Ren*,
Shilong Liu*,
Feng Li*,
Hao Zhang*,
Ailing Zeng,
Jie Yang,
Xingyu Liao,
Ding Jia,
Hongyang Li,
He Cao,
Jianan Wang,
Zhaoyang Zeng,
Xianbiao Qi,
Yuhui Yuan,
Jianwei Yang,
Lei Zhang†
Tech report, May. 2023
|
|
|
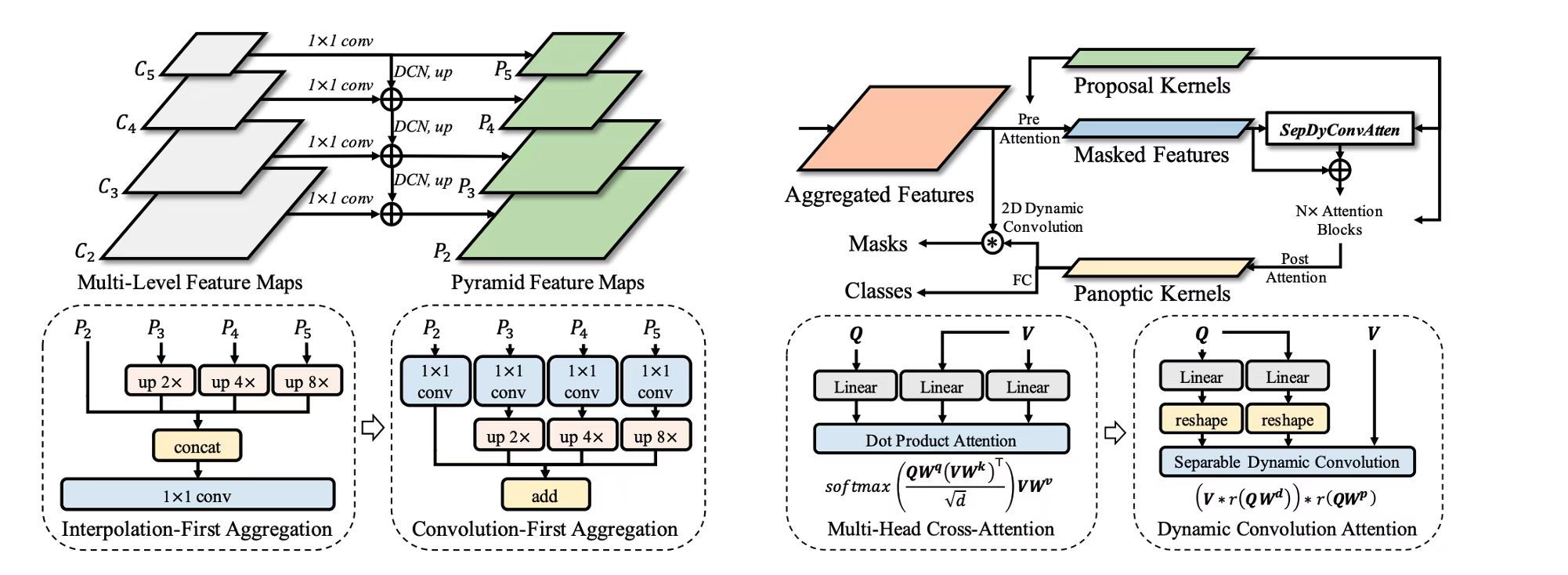
You Only Segment Once: Towards Real-Time Panoptic Segmentation
Jie Hu,
Linyan Huang,
Tianhe Ren,
Shengchuan Zhang,
Rongrong Ji,
Liujuan Cao†,
Computer Vision and Pattern Recognition (CVPR), 2023
|
|
|
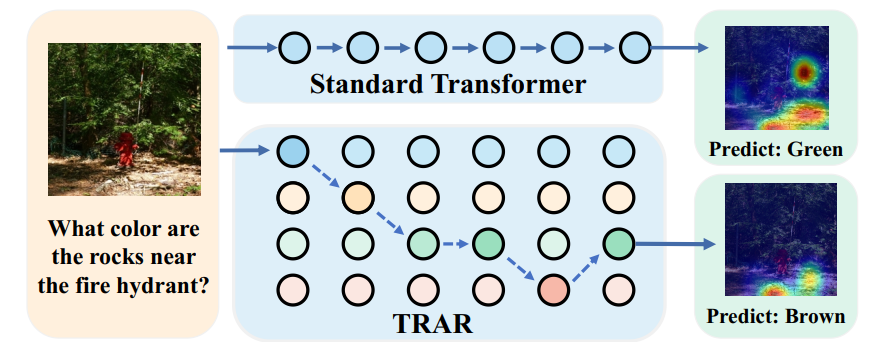
TRAR: Routing the Attention Spans in Transformers for Visual Question Answering
Yiyi Zhou,
Tianhe Ren,
Chaoyang Zhu ,
Xiaoshuai Sun,
Jianzhuang Liu,
Xinghao Ding,
Mingliang Xu,
Rongrong Ji†
International Conference on Computer Vision (ICCV), 2021
|
|
|
International Digital Economy Academy (IDEA)
Senior Computer Vision Engineer and Researcher
2022 - Present
Advisor: Lei Zhang
-
•
Leading research and development of vision foundation models
-
•
Developed high-impact open-source projects
|
|
|
OneFlow (SiliconFlow Now)
Computer Vision Engineer
2021 - 2022
Advisor: Jinhui Yuan
-
•
Develop deep learning frameworks and computer vision models
-
•
Contribute to OneFlow's computer vision ecosystem
|
|
|
MAC Lab, Xiamen University
Research Assistant
2019 - 2021
Advisors: Yiyi Zhou and
Rongrong Ji
-
•
Conducted research on multi-modal learning
|
Professional Services
Conference Reviewer
2026
-
•
Winter Conference on Applications of Computer Vision (WACV)
-
•
Artificial Intelligence and Statistics (AISTATS)
-
•
International Conference on Learning Representations (ICLR)
-
•
Computer Vision and Pattern Recognition (CVPR)
2025
-
•
International Conference on Learning Representations (ICLR)
-
•
Artificial Intelligence and Statistics (AISTATS)
-
•
Computer Vision and Pattern Recognition (CVPR)
-
•
International Conference on Machine Learning (ICML)
-
•
International Conference on Computer Vision (ICCV)
-
•
Conference on Neural Information Processing Systems (NeurIPS)
2024
-
•
Computer Vision in the Wild (CVinW) Workshop at CVPR
-
•
European Conference on Computer Vision (ECCV)
-
•
Conference on Neural Information Processing Systems (NeurIPS)
Workshop Organizer
-
•
Computer Vision in the Wild (CVinW) Workshop at CVPR 2025
-
•
Computer Vision in the Wild (CVinW) Workshop at CVPR 2023
|
|